Conductor Architecture and Worker Polling
To learn how to scale and integrate with Orkes Conductor, it is important to understand its system architecture and worker polling mechanism.
Before you read this article, you should understand:
System architecture
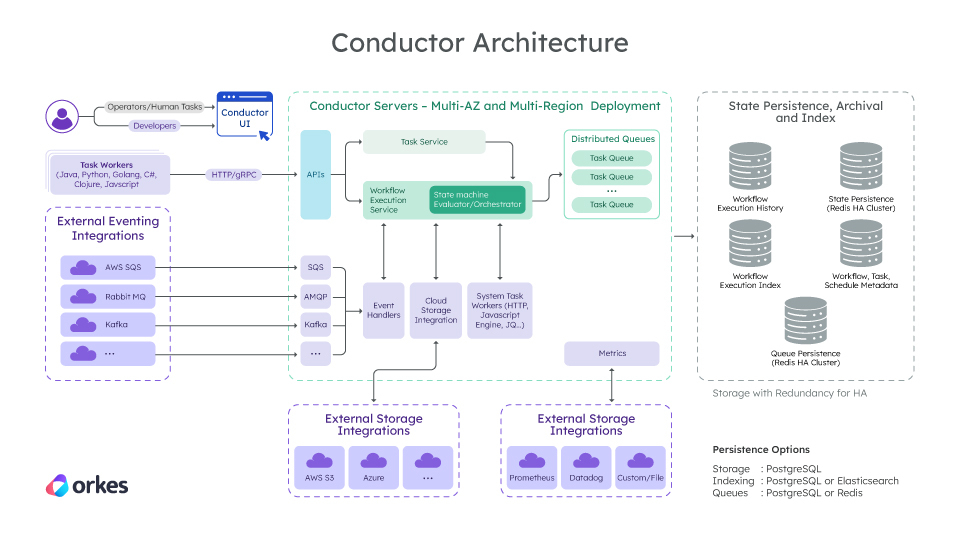
In Conductor, a workflow contains tasks in a defined order. You can trigger workflows by code, an API call, a cron schedule, webhooks, or external eventing systems such as AWS SQS, Kafka, Azure Service Bus, GCP Pub/Sub, AMQP, NATS, and IBM MQ.
The FIFO (first in, first out) guarantee applies to task execution within a running workflow. When workflows are triggered by external systems like Kafka, ordering depends on how those systems deliver messages and is not covered by Conductor's internal task queue ordering.
In Conductor, workflows are executed on a worker-task queue architecture, where each task type (HTTP, Event, Wait, and so on) has its own dedicated task queue. The key components of Conductor’s core orchestration engine include:
- State machine evaluator: Orchestrates workflows by scheduling tasks to their relevant queues and assigning them to active workers when polled. Monitors each task's state and ensures it is completed, retried, or failed as required.
- Task queues: Distributed queues for each task type, where tasks are completed on a first-in-first-out basis.
- Task workers: Poll the Conductor server via HTTP for tasks, execute tasks, and update the server on the task status. Each worker is responsible for carrying out a specific task type.
- Data stores (Postgres or Redis): High-availability persistence stores that maintain workflow and task metadata, task queues, and execution history
- APIs: REST APIs for programmatic access to the Conductor server.
Integrations with tools such as Prometheus and Datadog enable you to collect and monitor system performance data easily. Prometheus metrics can be visualized using Grafana.
Worker implementation
System task workers are managed by Conductor. On the other hand, external workers can be implemented in any language and can run on any environment, including bare metal, containers, VMs, or serverless functions. Conductor offers SDKs with features such as polling threads, metrics, and server communication to simplify worker creation.
Worker-server polling mechanism
Each worker declares beforehand which tasks it can execute, and the Conductor server assigns tasks to workers accordingly. At runtime, task workers poll the Conductor server to receive and execute scheduled work. Conductor passes task inputs to the worker for execution and collects the outputs, continuing the process according to the workflow definition.
By default, workers infinitely poll Conductor every 100ms. This interval is configured in the worker's SDK and can be adjusted based on workload. Here is the polling mechanism in detail:
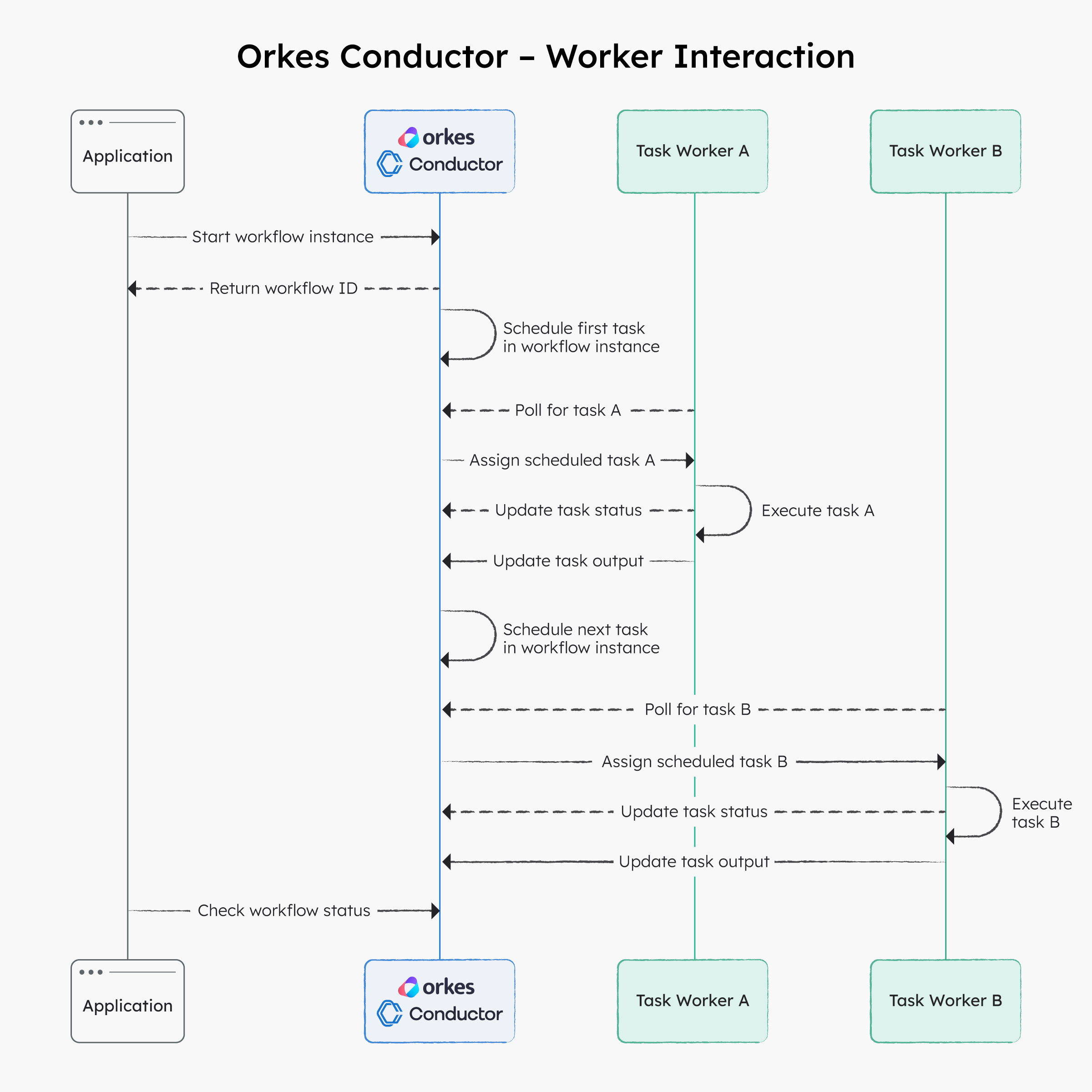
The following sequence describes how workers poll Conductor and execute workflow tasks:
- The application starts a workflow execution by interacting with Orkes Conductor, which returns a workflow (execution) ID. It can be used to track the workflow's progress and manage its execution.
- Conductor schedules the first task in the workflow to its task queue.
- The workers responsible for executing the first task within the workflow are polling Orkes Conductor for tasks to execute via HTTP. When a task is scheduled, Conductor sends it to the next available worker, which then performs the required work.
- Periodically, the worker returns the task status to the Conductor (e.g., IN PROGRESS, FAILED, COMPLETED, etc.).
- Once the first task in the workflow execution is completed, the worker returns the task output to the server, and Conductor schedules the next set of tasks to be performed.
Conductor manages and maintains the workflow state, keeping track of which tasks have been completed and which are still pending. This ensures that the workflow is executed correctly, with each task triggered precisely at the right time.
Using the workflow ID, the application can check the Conductor server for the workflow status at any time. This is particularly useful for asynchronous or long-running workflows, as it enables the application to monitor their progress and take appropriate action, such as pausing or terminating them if needed.