Build a Question Answering Workflow Using Stored Embeddings
This tutorial demonstrates how to build a question-answering workflow in Orkes Conductor using embeddings generated from text provided directly as workflow input.
The workflow converts the raw text supplied to it into embedding vectors, stores those vectors in a vector database, retrieves relevant content at query time, and answers a user’s question using the retrieved context. This is a simple and realistic example of retrieval augmented generation (RAG).
Unlike document-based retrieval workflows, this example embeds text passed directly through workflow input rather than indexing content from external documents or URLs.
In this tutorial, you will:
- Integrate an AI model provider
- Create a prompt for answering questions with context
- Integrate Pinecone as the vector database
- Build a workflow that generates, stores, and retrieves embeddings
- Run the workflow and verify the answer
To follow along, ensure you have access to the free Orkes Developer Edition.
The embedding index and query workflow
The workflow uses OpenAI to generate embeddings and Pinecone to store and retrieve them. You can replace it with any supported provider.
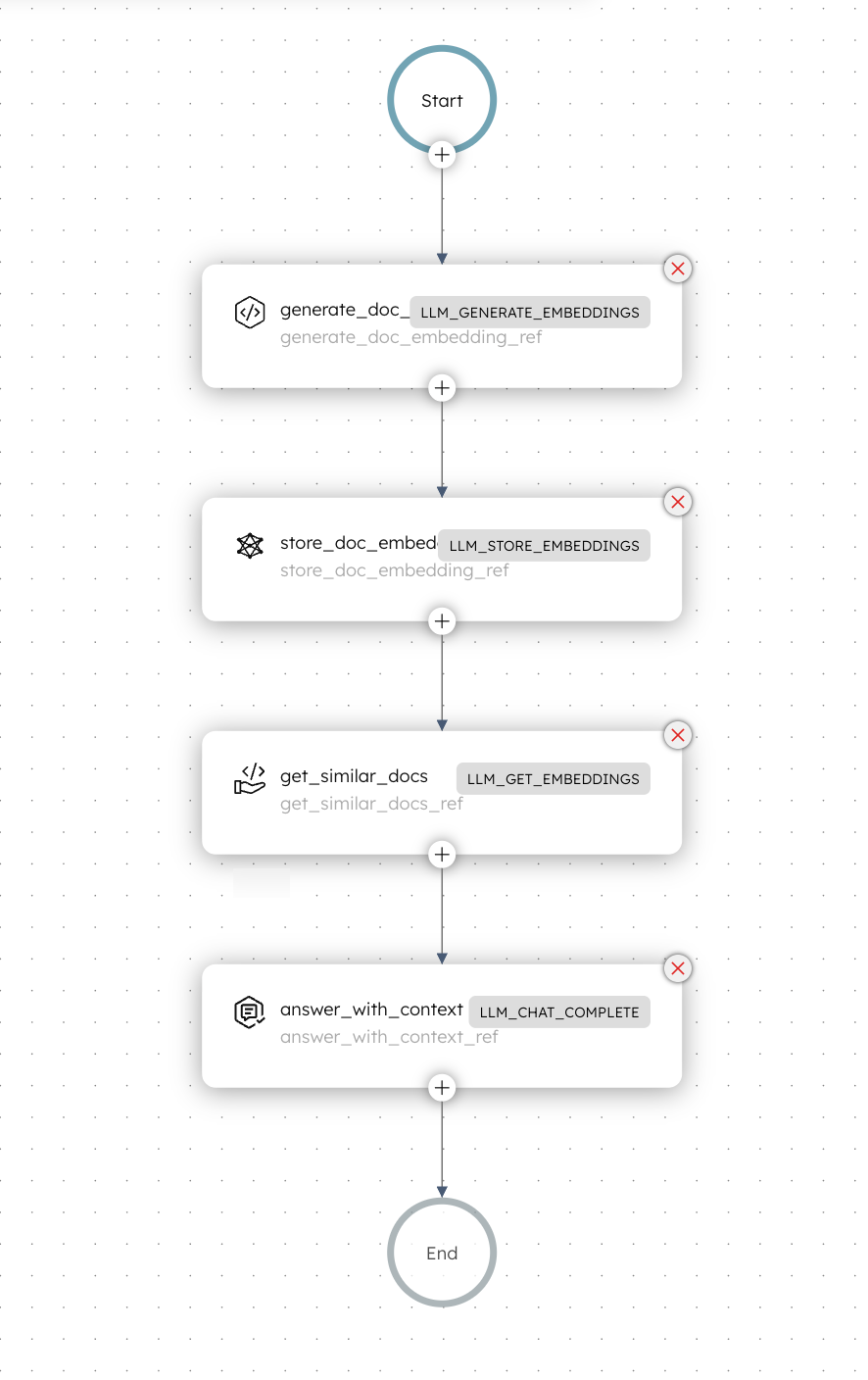
Here is the RAG workflow that you’ll build in this tutorial:
Workflow input:
- text: The document text that will be converted to embeddings.
- docId: A unique identifier for the document ID to be stored in the Pinecone database.
- queryText: The question that the workflow must answer using the retrieved context.
Workflow logic:
- The workflow begins with an LLM Generate Embeddings task that converts the input text into a high-dimensional embedding vector.
- The generated embedding is then stored in a Pinecone index using an LLM Store Embeddings task.
- Next, an LLM Get Embeddings task retrieves the most similar document from Pinecone by performing a vector similarity search using the same embedding.
- An LLM Chat Complete task answers the query by combining the retrieved document text as context with the prompt instructions.
Workflow output:
- answer - The final answer generated by the LLM based on the retrieved context and question.
This workflow is best suited for scenarios where the content to be queried is already available as text, rather than stored in external documents that need to be ingested and indexed.
In this example, the workflow uses the embedding generated from the input text both to store the document in the vector database and to retrieve similar content. This is done to keep the example simple and focused on the end-to-end flow.
Step 1: Integrate an AI model provider
Add an OpenAI integration to your Conductor cluster, then add the required model.
Add OpenAI integration
To add an OpenAI integration:
- Get your OpenAI API Key from OpenAI’s platform.
- Go to Integrations from the left navigation menu on your Conductor cluster.
- Select + New integration.
- Create the integration by providing the following mandatory parameters:
- Integration name: “openAI”
- API Key:
<YOUR_OPENAI_API_KEY> - Description: “OpenAI Integration”
- Ensure that the Active toggle is switched on, then select Save.
The OpenAI integration has been added. The next step is to add a specific model.
Add models
You will add two models to your OpenAI integration:
- text-embedding-3-large – Used to generate embeddings from the input text.
- chatgpt-4o-latest – Used to generate an answer using the retrieved context.
To add a model:
- In the Integrations page, select the + button next to your newly-created OpenAI integration.
- Select + New model.
- Enter the Model Name as “text-embedding-3-large” and an optional description like “OpenAI’s text-embedding-3-large model”.
- Ensure that the Active toggle is switched on and select Save.
Repeat the steps and create a model for chatgpt-4o-latest.
The integration is now ready to use. The next step is to create an AI prompt for the LLM Chat Complete task, which the workflow uses to generate answers from retrieved context.
Step 2: Create the AI prompt
To create an AI prompt:
- Go to Definitions > AI Prompts from the left navigation menu on your Conductor cluster.
- Select + Add AI prompt.
- In Prompt Name, enter a unique name for your prompt, such as RAG_Answer_With_Context.
- In Model(s), select the OpenAI integration you configured earlier. The dropdown lists the integration and its available models. Choose openAI:chatgpt-4o-latest for this prompt.
- Enter a Description of what the prompt does. For example: “Generates an answer to a user question using only the provided context retrieved from a vector database.”
- In Prompt Template, enter the following prompt:
You are an assistant that answers questions using only the provided context.
If the context does not contain the answer, say that the information is not available.
Keep your responses short and clear.
Question: ${queryText}
Context:
${retrievedContext}

Here, we have defined ${queryText} and ${retrievedContext} as variables derived from the workflow input and the output of previous tasks. This will become clearer once we incorporate this prompt into the workflow.
- Select Save > Confirm save.
This saves your prompt.
Step 3: Integrate Pinecone as the vector database
The workflow uses Pinecone to store and retrieve embedding vectors. Add a Pinecone integration to your Conductor cluster and create the index required for this workflow.
Get credentials from Pinecone
To get your Pinecone credentials:
- Log in to the Pinecone console, and get the API key and project ID.
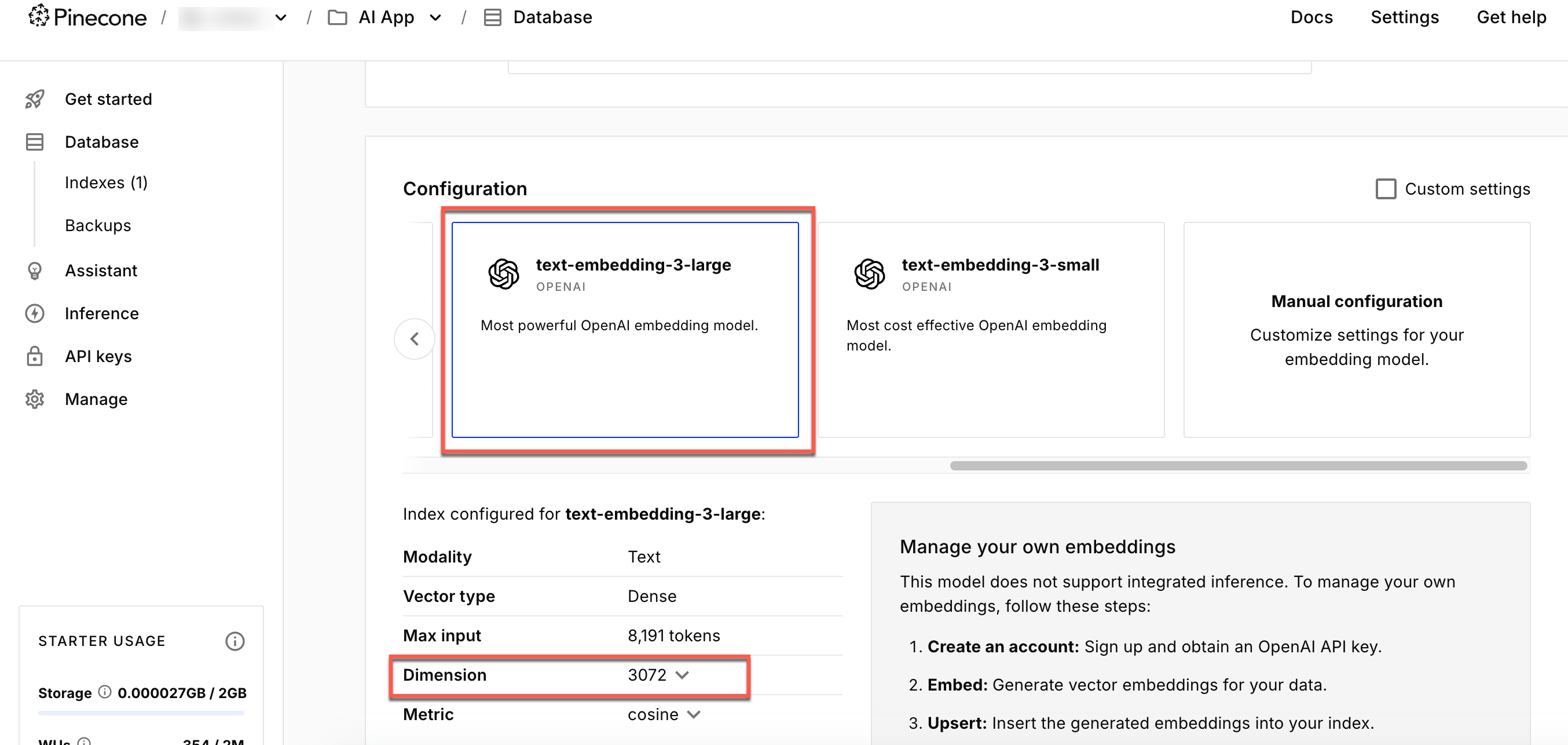
- Create an index, setting the Configuration to text-embedding-3-large and the Dimension to 3072.
- Note the index name, as you will need to reference it when setting up the Pinecone integration in Conductor.
The text-embedding-3-large model generates vectors with a dimension of 3072. Your Pinecone index must be configured with this same dimension to store and query embeddings correctly. A mismatched dimension will cause Conductor workflow failures.
Add Pinecone integration
To create a Pinecone integration in Conductor:
- Go to Integrations from the left navigation menu on your Conductor cluster.
- Select + New integration.
- Create the integration by providing the following details:
- Integration name: Enter Pinecone.
- API Key:
<YOUR-PINECONE-API-KEY>. - Project name:
<YOUR-PINECONE-PROJECT-NAME>. - Environment: Your index’s region name.
- Description: An optional description.
- Ensure that the Active toggle is switched on, then select Save.
Add indexes
The next step is to add the index to the Conductor cluster.
To add an index:
- In the Integrations page, select the + button next to your newly-created Pinecone integration.
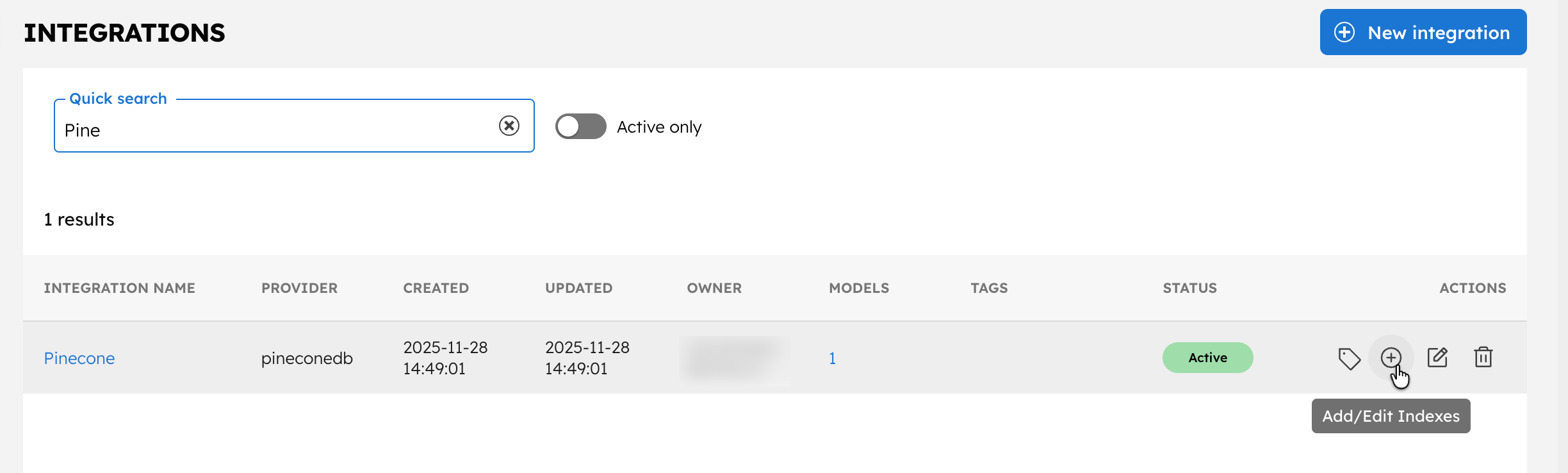
- Select + New Index.
- Enter the Index name as
<YOUR-INDEX-NAME-IN-PINECONE>and a description. - Ensure that the Active toggle is switched on and select Save.
With the integrations and prompt ready, let’s create the workflow.
Step 4: Create the embedding index and query workflow
To create a workflow:
- Go to Definitions > Workflow and select + Define workflow.
- In the Code tab, paste the following JSON:
{
"name": "RAG_Index_Query_Workflow",
"description": "Generate embeddings, store in Pinecone, retrieve similar content, and answer a query",
"version": 1,
"tasks": [
{
"name": "generate_doc_embedding",
"taskReferenceName": "generate_doc_embedding_ref",
"inputParameters": {
"llmProvider": "<YOUR-LLM-PROVIDER>",
"model": "<YOUR-LLM-MODEL>",
"text": "${workflow.input.text}",
"dimensions": 3072
},
"type": "LLM_GENERATE_EMBEDDINGS"
},
{
"name": "store_doc_embedding",
"taskReferenceName": "store_doc_embedding_ref",
"inputParameters": {
"vectorDB": "<YOUR-VECTOR-DB-INTEGRATION>",
"index": "<YOUR-INDEX-NAME>",
"namespace": "rag_demo",
"id": "${workflow.input.docId}",
"embeddings": "${generate_doc_embedding_ref.output.result}",
"metadata": {
"text": "${workflow.input.text}"
},
"embeddingModelProvider": "<YOUR-LLM-PROVIDER>",
"embeddingModel": "<YOUR-LLM-MODEL>"
},
"type": "LLM_STORE_EMBEDDINGS"
},
{
"name": "get_similar_docs",
"taskReferenceName": "get_similar_docs_ref",
"inputParameters": {
"vectorDB": "<YOUR-VECTOR-DB-INTEGRATION>",
"index": "<YOUR-INDEX-NAME>",
"namespace": "rag_demo",
"embeddings": "${generate_doc_embedding_ref.output.result}"
},
"type": "LLM_GET_EMBEDDINGS"
},
{
"name": "answer_with_context",
"taskReferenceName": "answer_with_context_ref",
"inputParameters": {
"llmProvider": "<YOUR-LLM-PROVIDER>",
"model": "<YOUR-LLM-MODEL>",
"instructions": "<YOUR-LLM-PROMPT>",
"messages": [
{
"role": "user",
"message": "Question: ${workflow.input.queryText}\n\nContext:\n${get_similar_docs_ref.output.result[0].text}"
}
],
"temperature": 0,
"topP": 0,
"jsonOutput": false,
"promptVariables": {
"retrievedContext": "${get_similar_docs_ref.output.result[0].metadata.text}",
"queryText": "${workflow.input.queryText}"
}
},
"type": "LLM_CHAT_COMPLETE"
}
],
"inputParameters": [
"text",
"docId",
"queryText"
],
"outputParameters": {
"answer": "${answer_with_context_ref.output.result}"
},
"schemaVersion": 2
}
- Select Save > Confirm.
- After saving, update the LLM Generate Embeddings task with your actual values:
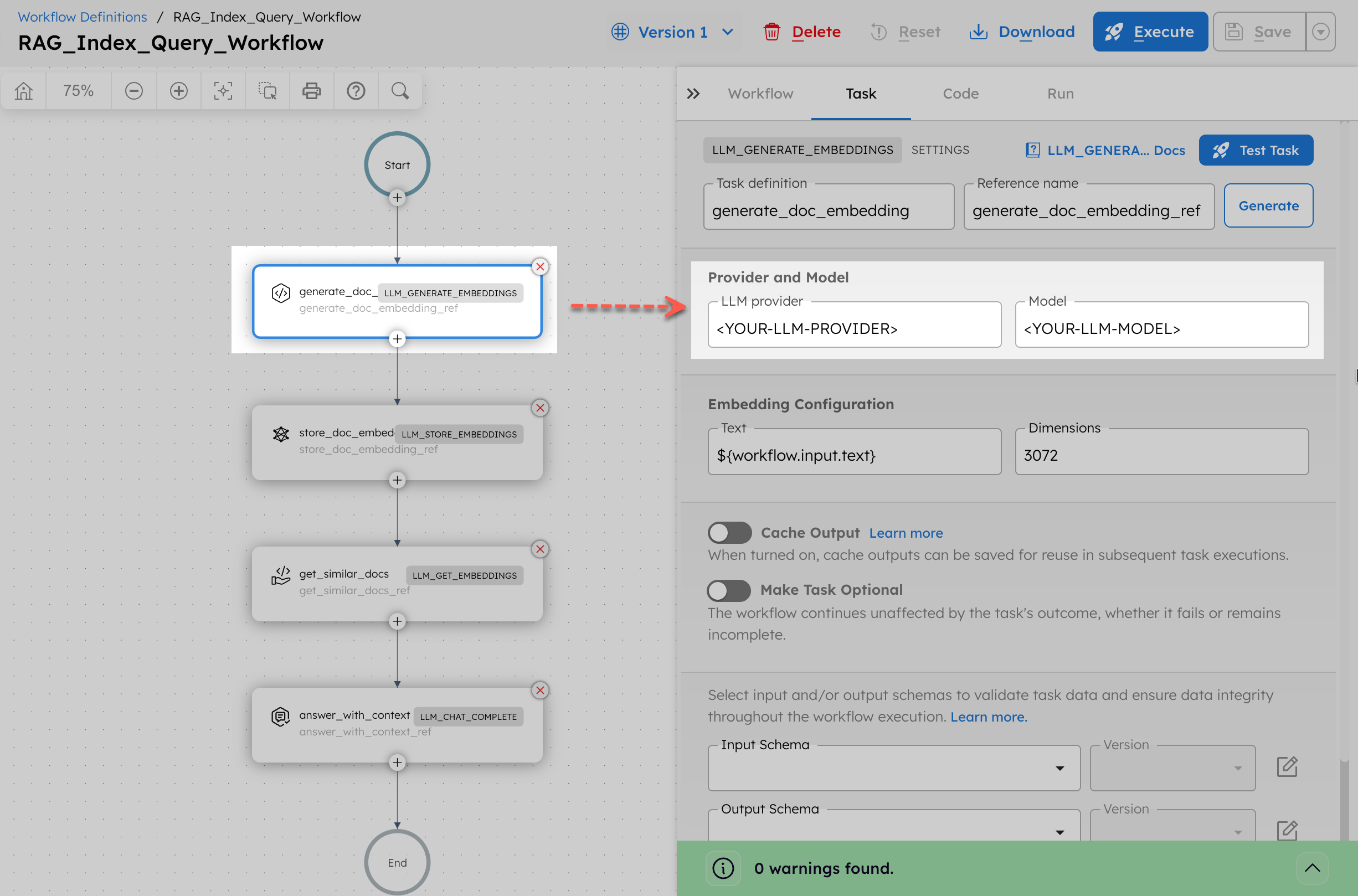
- In LLM provider, replace
<YOUR-LLM-PROVIDER>with your OpenAI integration name created in Step 1. - In Model, replace
<YOUR-LLM-MODEL>withtext-embedding-3-large.
- Update the LLM Store Embeddings task with your actual values:
- In Vector database, replace
<YOUR-VECTOR-DB-INTEGRATION>with your integration name created in Step 3. - In Index, replace
<YOUR-INDEX-NAME>with your index name created in Step 3. - In Embedding model provider, replace
<YOUR-LLM-PROVIDER>with your OpenAI integration name created in Step 1. - In Model, replace
<YOUR-LLM-MODEL>withtext-embedding-3-large.
- In Vector database, replace
- Update the LLM Get Embeddings task with your actual values:
- Update the LLM Chat Complete task with your actual values:
- In LLM provider, replace
<YOUR-LLM-PROVIDER>with your OpenAI integration name created in Step 1. - In Model, replace
<YOUR-LLM-MODEL>withchatgpt-4o-latest. - In Prompt template, replace
<YOUR-LLM-PROMPT>with your prompt created in Step 2. - Make sure to update the promptVariable as follows:
- retrievedContext -
${get_similar_docs_ref.output.result[0].metadata.text} - queryText -
${workflow.input.queryText}
- retrievedContext -
- In LLM provider, replace
- Select Save > Confirm.
Step 5: Run the workflow
To run the workflow using Conductor UI:
- From your workflow definition, go to the Run tab.
- Enter the Input Params.
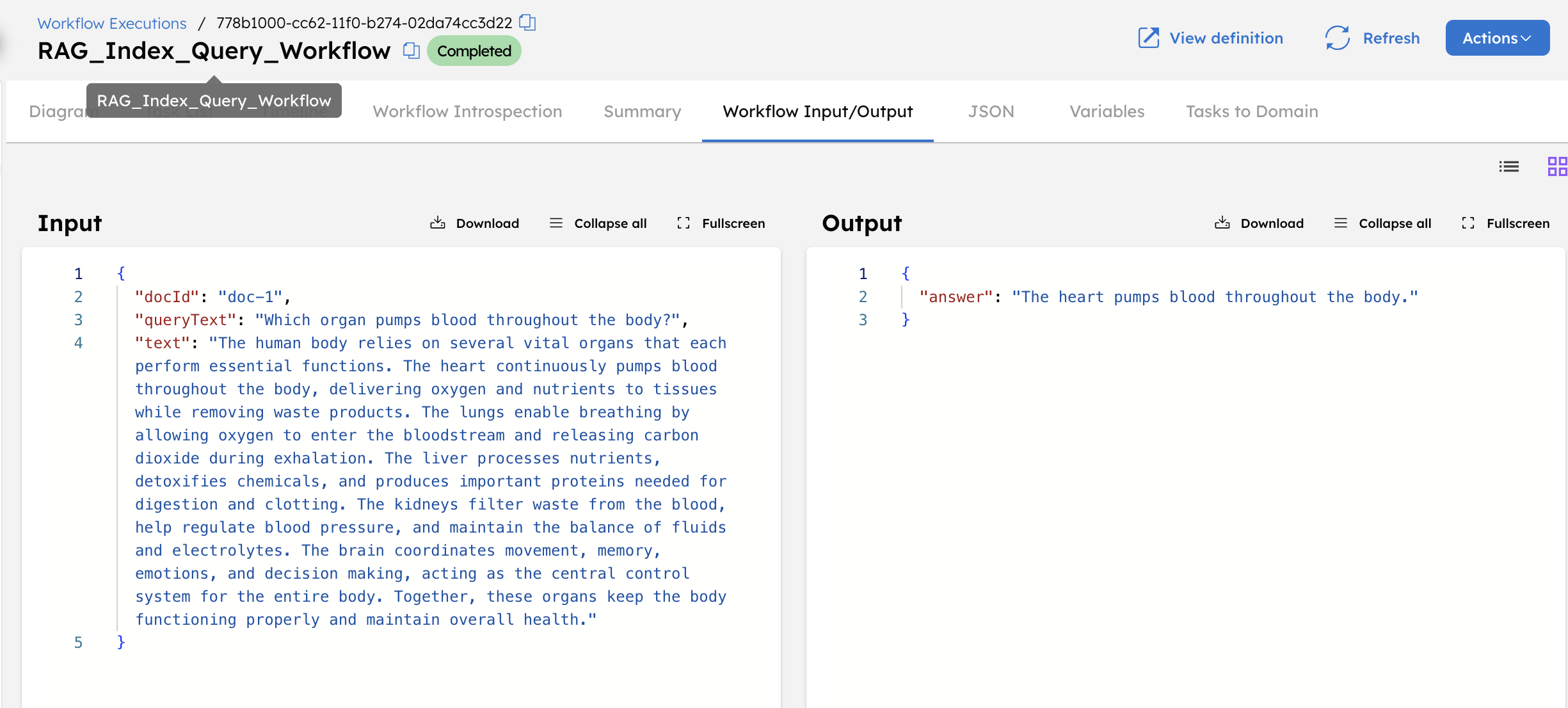
// example input params
{
"text": "The human body relies on several vital organs that each perform essential functions. The heart continuously pumps blood throughout the body, delivering oxygen and nutrients to tissues while removing waste products. The lungs enable breathing by allowing oxygen to enter the bloodstream and releasing carbon dioxide during exhalation. The liver processes nutrients, detoxifies chemicals, and produces important proteins needed for digestion and clotting. The kidneys filter waste from the blood, help regulate blood pressure, and maintain the balance of fluids and electrolytes. The brain coordinates movement, memory, emotions, and decision making, acting as the central control system for the entire body. Together, these organs keep the body functioning properly and maintain overall health.",
"docId": "doc-1",
"queryText": "Which organ pumps blood throughout the body?"
}
- Select Execute.
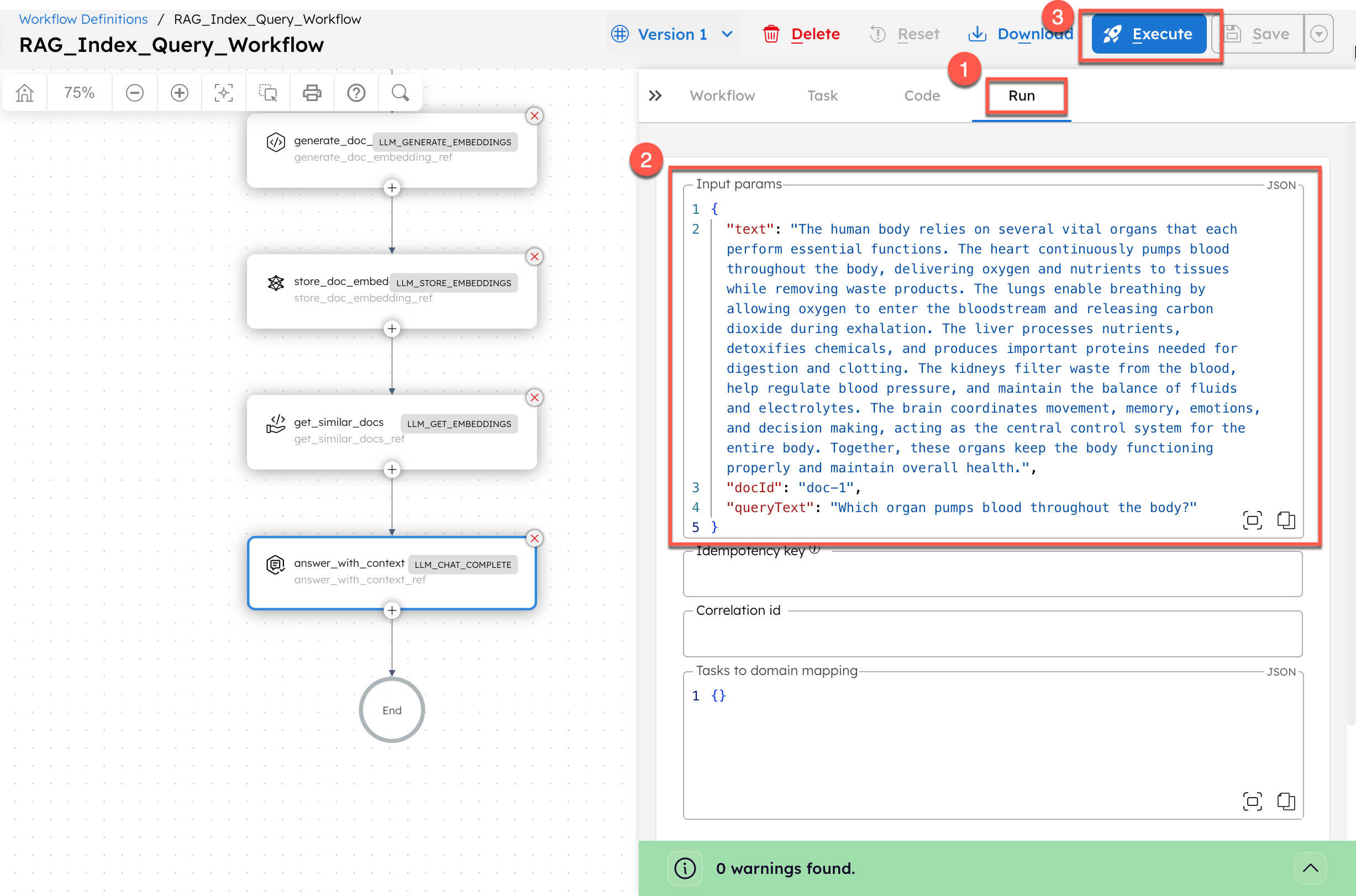
The workflow retrieves the stored text and generates an answer.